
Parking and Security Management Made Easy
Take Command of Your Parking and Security
OperationsCommander (OPS-COM) offers a streamlined solution for permit administration, parking enforcement, and incident reporting, making parking and security management efficient and cost-effective.









One System – One Platform – One Database
Boost your parking and security management with an all-in-one cloud platform that grows as you do.
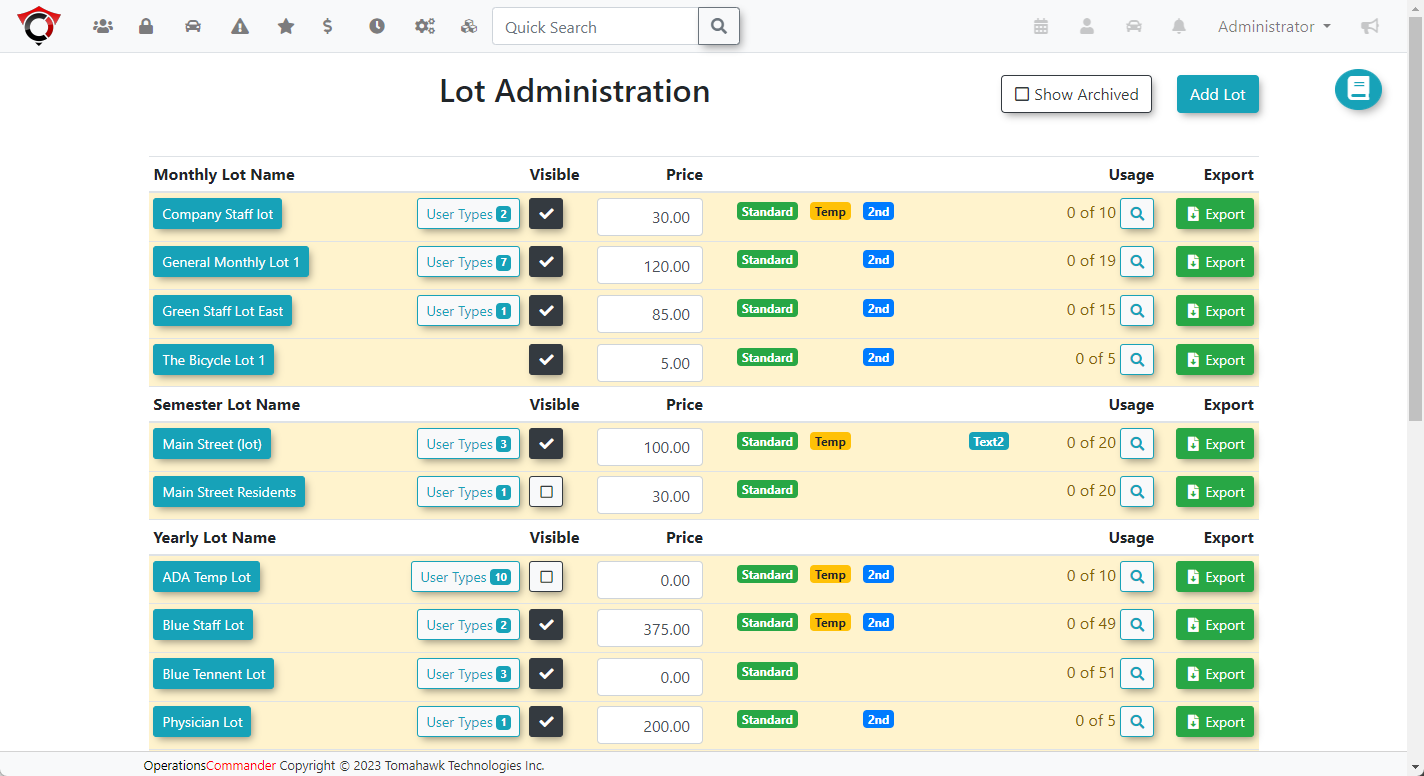

ParkAdmin
Sell, track, and manage
parking permits online.

ViolationAdmin
Simplify violation management
using mobile technology.

IncidentAdmin
Efficiently handle incidents
with detailed reports.
Manage Your Entire Parking & Security Operation in One Place
OperationsCommander is a complete security management platform designed to meet the needs of any security office, no matter its size.
With platform-as-a-service, the OperationsCommander platform can integrate with any legacy system.

Validate Plates Without Leaving Your Vehicle
OperationsCommander offers flexible management of parking and security operations. Staff can perform transactions from anywhere using a mobile device and validate plates without leaving their vehicle.
Prioritize staff safety while ensuring top-notch client service.
Create a Virtual Permit Environment with Automated License Plate Recognition
OperationsCommander integrates with three types of LPR (fixed and mobile) and offers simple Android integration. Mobile ANPR hardware is so lightweight that patrols can easily transfer it from one vehicle to another. Static cameras allow 24/7 tracking, eliminating the need for multiple integrations, troubleshooting, and licensing fees.

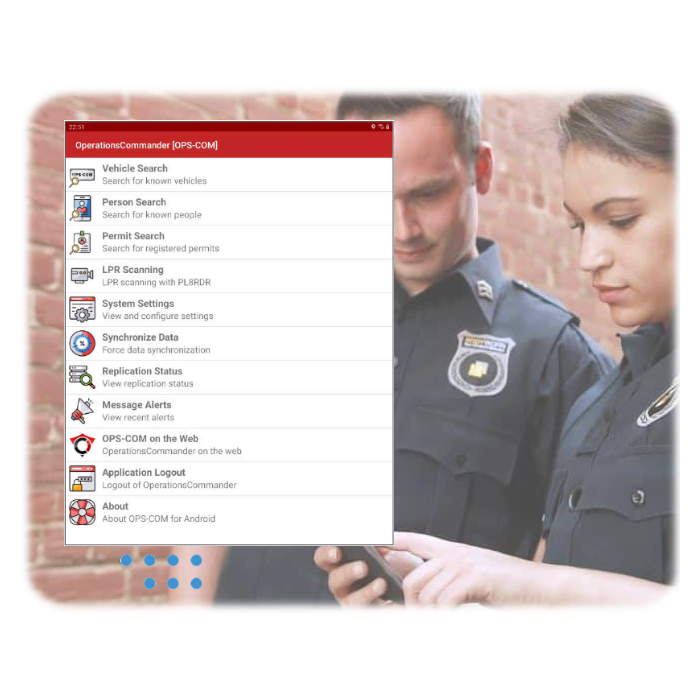
Parking Enforcement
with Real-Time Data
OperationsCommander offers in-the-field data queries with full data synchronization. Patrols have real-time access to data to validate vehicles using text search or LPR integration, which is as easy as taking a picture!
Proud Suppliers of
Parking & Security Success
We have built security and parking system tools that improve management and increase return on investment (ROI). All platform modules are designed to work together to share data in real-time throughout the system.
OperationsCommander clients have the data they need when they need it.
Solutions Tailored to Your Needs

Scalable Software
Whether you are looking for a security platform-as-a-service (PaaS) or a solution that offers parking software-as-a-service (SaaS), OperationsCommander offers a customizable management solution accessible from anywhere at any time of day.

License Plate Recognition
Reduce overhead costs, increase revenue, simplify patrols, and read license plates with our PL8RDR LPR system. We built the license plate recognition system to support many parking enforcement uses.

Self-Serve Temp Parking
Our Text2ParkMe and QR Code solutions offer an efficient, user-friendly mobile payment option without needing a mobile app. This offers an intuitive self-serve temporary parking interface to all users.
Reasons to Consider
OperationsCommander for Your Operation
Stay Informed, Stay Ahead..
Dive into the latest trends, news, and updates by subscribing to our newsletter.
Subscribe today and never miss a beat!
Read the Latest Articles on Parking & Security
- Revolutionizing Parking Operations: The Impact of LPR Technology
 In the fast-paced world of parking operations, efficiency is key. That’s where License Plate Recognition (LPR) technology steps in, transforming the landscape of parking management with its cutting-edge capabilities. Read…
In the fast-paced world of parking operations, efficiency is key. That’s where License Plate Recognition (LPR) technology steps in, transforming the landscape of parking management with its cutting-edge capabilities. Read… - How To Make The Parking Experience Better For Customers
 Introduction Parking can often be a source of frustration for drivers, whether it’s finding an available space, navigating complex permit systems, or dealing with enforcement issues. However, with OperationsCommander, customers…
Introduction Parking can often be a source of frustration for drivers, whether it’s finding an available space, navigating complex permit systems, or dealing with enforcement issues. However, with OperationsCommander, customers… - Maximizing Revenue: Strategies for Your Parking Operation
 In the cutthroat parking management industry, optimizing revenue for your parking venture is imperative for maintaining a competitive edge. At OperationsCommander, we understand the hurdles businesses big and small encounter…
In the cutthroat parking management industry, optimizing revenue for your parking venture is imperative for maintaining a competitive edge. At OperationsCommander, we understand the hurdles businesses big and small encounter… - Urbanization and the Digital DivideIn the rapid urbanization and digital advancement age, our cities are undergoing a remarkable transformation. The rise of smart cities is at the forefront of this change, promising improved quality…



